In this third blog of the series, I want to cover the management features of the HPE Alletra array. There are two options here: the on-system GUI or the GreenLake Data Services Cloud Console (DSCC). I think it’s fair to say that DSCC is the preferred array management method. As time passes, more functionality and orchestration will be added to the Cloud-based DSCC application and the broader suite of Cloud-based management applications.
But for now, let’s discover what both options involve!
On-system GUI
At the time of writing, certain specific tasks will require the on-system GUI.
The first thing that strikes me about the on-system GUI (local web interface) is how straightforward and user-friendly it is. All of the high-level status information you’d expect to see is available right on the dashboard page.
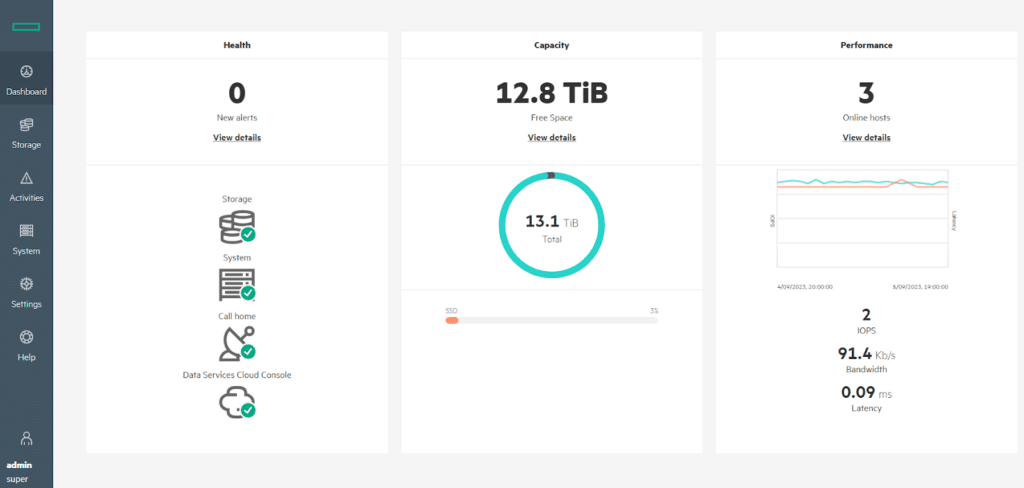
For example, most objects on the dashboard can be selected to view more detailed information, such as data trending and more granular system status
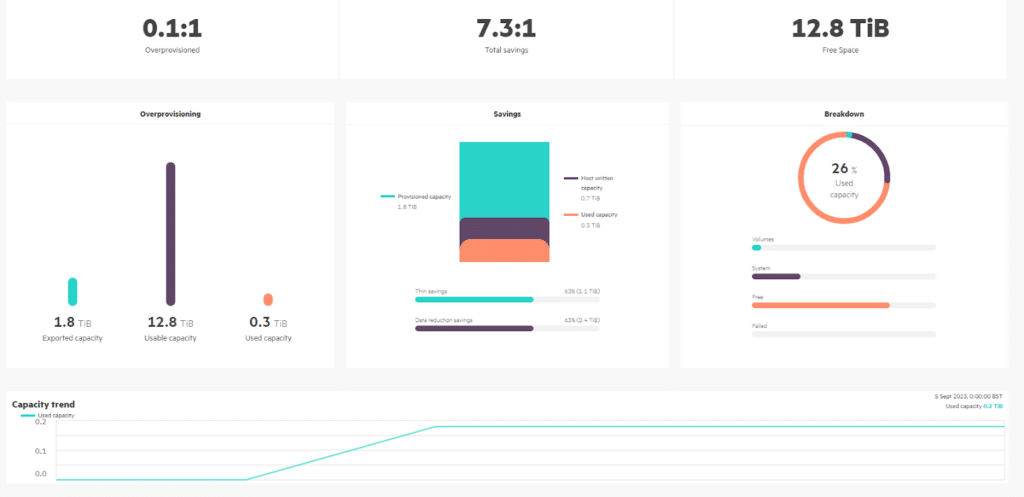
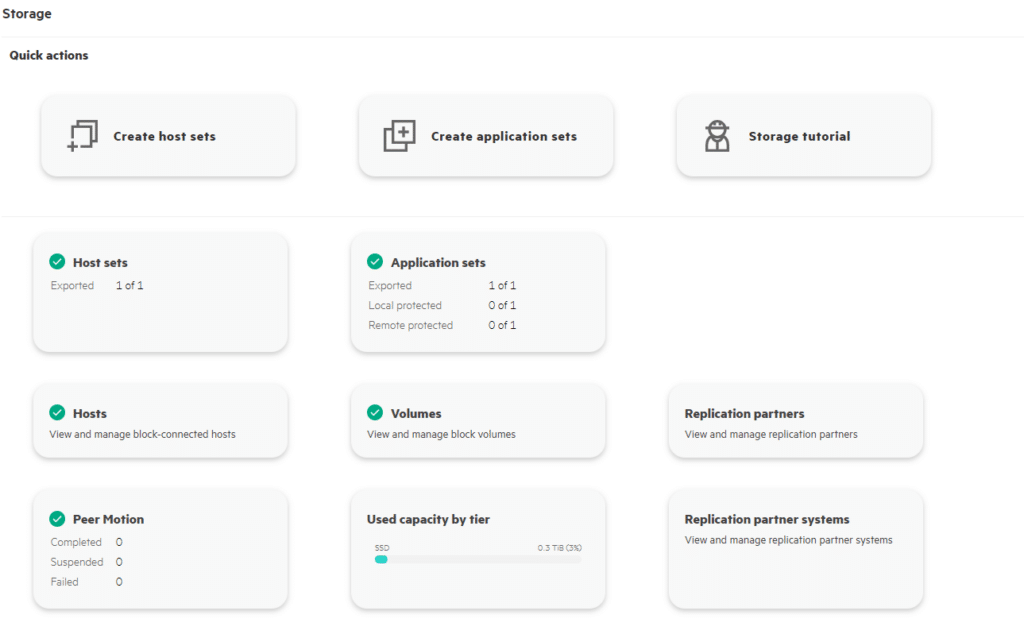
With that said, I was slightly disappointed that there isn’t a real-time performance monitoring page; perhaps that’s something for the future.
Encryption at rest is configurable using either Local Key or External Key Management. The system supports local and LDAP authenticated users – for AD, OpenLDAP and Red Hat Directory Server.
I won’t spend more time on this because, as I said, the preferred management method is via the DSCC.
GreenLake Data Services Cloud Console (DSCC)
DSCC is part of the GreenLake application suite, alongside Aruba Central, Compute Ops Management and HPE GreenLake Central. DSCC allows us to manage our Alletra storage arrays from the GreenLake Platform. This isn’t new or unique to the Alletra MP as it is available across most of the HPE Alletra storage range (5k, 6k and 9k). However, it is an essential solution piece that is regularly updated with new features.
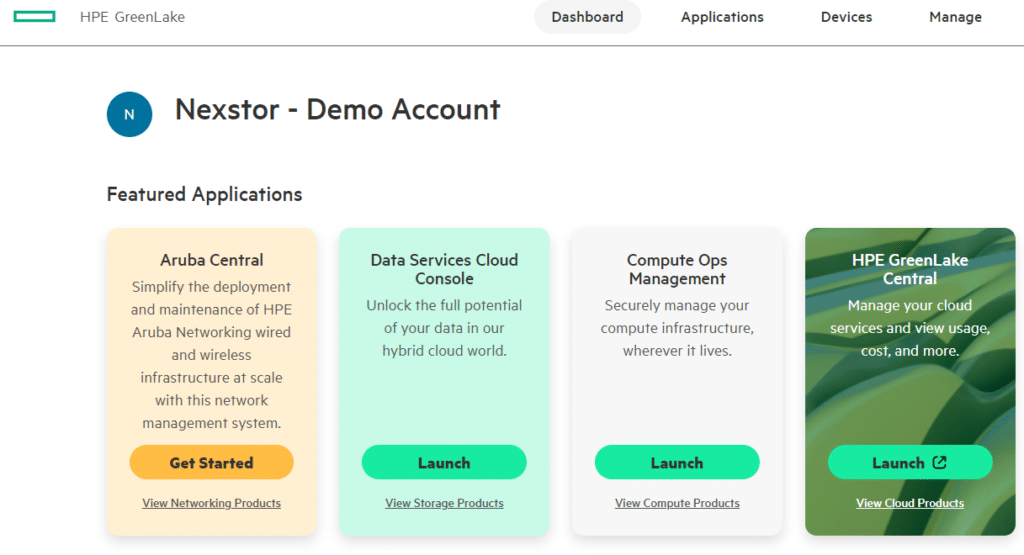
The DSCC includes several tiles from which you can access various functionality. The two tiles relevant to the Alletra MP for Block are “Data Ops Manager” and “Block Storage”. I’ll quickly go through each in turn so you get a feel for what each one does.
Data Ops Manager
The Data Ops Manager is the place to be for all things Data. It’s an area where you can view information on your systems, configure data access groups for your system, and link into the Block Storage and File storage areas.
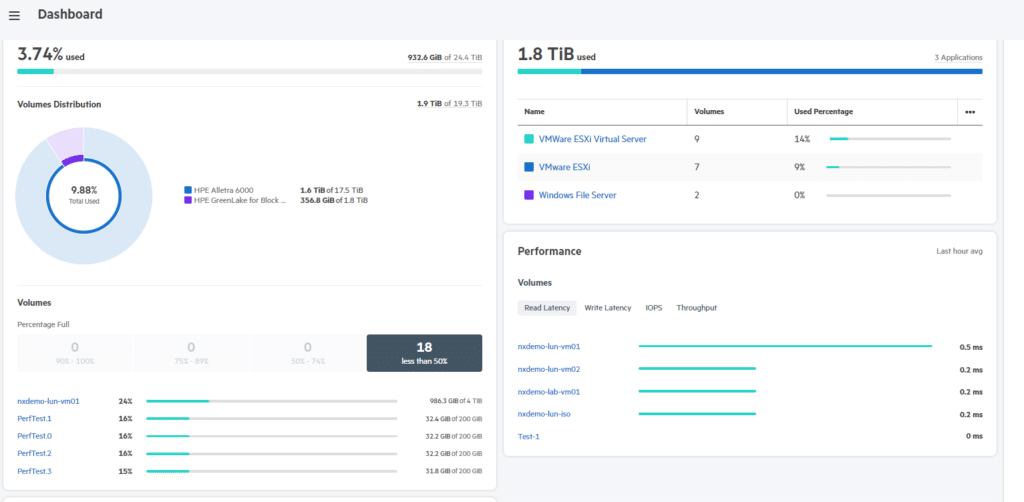
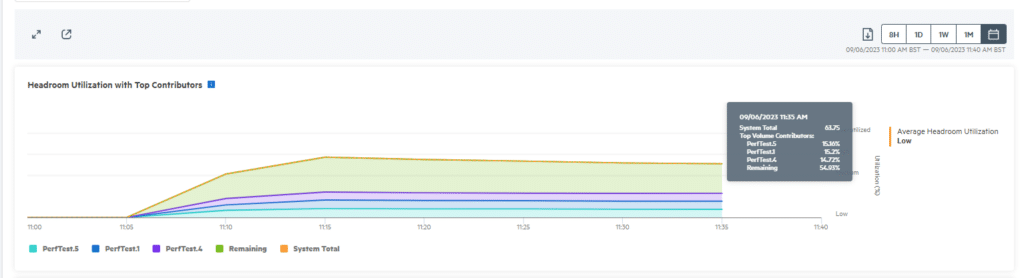
The dashboard gives you a good overview of what’s going on in your storage environment. It’s a place to view insights into your systems, such as IOPs, latency, average block size, system headroom and much more. The section on headroom is a particularly excellent addition, empowering administrators to view how much more load can be added to the system before it hits the ceiling.
The various views allow you to view your systems over pretty much any time frame you like so that you can see trends over time, helping with capacity planning.
I also like that the performance metrics can be viewed based on Hosts and Hosts’ ports. This could be useful when trying to diagnose performance-related issues.
Block Storage
The Block Storage section is where you can view and provision storage. Our Demo GreenLake environment has two storage arrays – an Alletra 6030 All-Flash array and the new Alletra MP for Block array.
This is where DSCC comes into particular use. When you have multiple storage arrays that you need to manage — whether on the same site or distributed across the globe — you can log into your own instance of DSCC and start provisioning. There’s no need to hop around various VPNs and/or user interfaces to access a particular array you wish to work with; it’s all available under the DSCC.
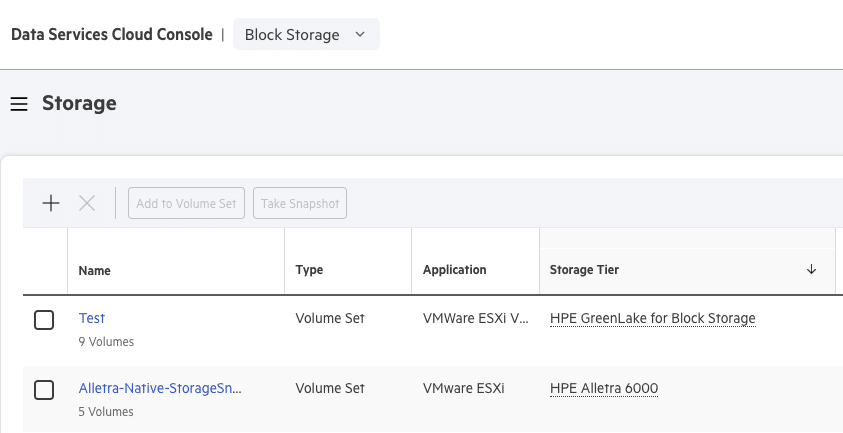
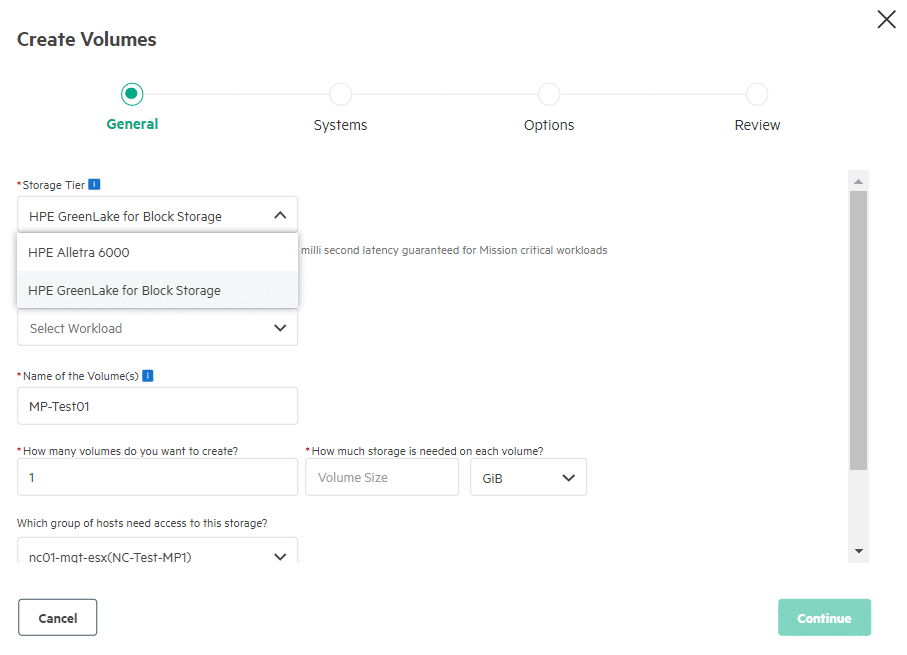
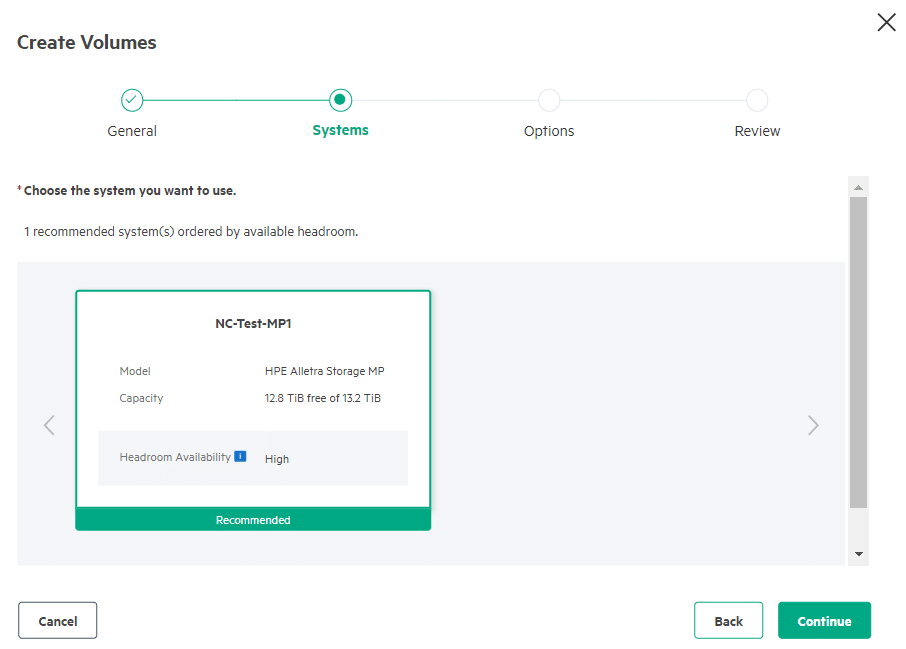
Volumes are created using the concept of “Intent-based provisioning”. The Platform helps you place the volumes on the appropriate system based on the application type and the expected performance requirement. The system quickly checks to ensure that you have selected a host group that is visible to the array and has enough capacity. Additional options include adding a Quality of Service at the volume set level: 5 levels, Low through to High, and this kicks in when there is contention.
The best feature that comes with intent-based provisioning is that it references the data in the system headroom statistics. Intent provisioning recommends the best fit for the workload placement, taking into account available headroom across the system. It then simulates the application workload patterns to estimate the available headroom after placement.
Personally, I think this is very cool. Good work, HPE!
So, to summarize, it’s an easy-to-use interface with some powerful features. I really like it and am looking forward to seeing what functionality is added in the future.
A final note on performance
I did carry out several performance tests, just because that’s what you do when you’ve got a new toy, right? You see how fast it can go.
HPE provides performance data in their sizing tools, based on various metrics and system configurations. So I based my tests on those metrics. I won’t document the results here as they are unofficial results, but I’d summarize and say that I saw improvements in those official figures.
I was testing using our small loan system, and the fact is that the GreenLake for Block system is so modular and scalable that most use cases and configurations can match that workload.
Curious to know more? Stick around for the final blog in this series, where I will go more in-depth on the insights I found as a result of these tests.
Meanwhile, our team of experts here at Nexstor can give you some more bespoke advice on how HPE’s offers can match your business needs. Just contact us to get a conversation started.
")

Share: